Turning a Home Server Into a Production Environment
A record of adding deployment, observability, and backup routines to a home server and reaching an App Store launch.
The Hangangjari server was split into a FastAPI backend, workers, PostgreSQL/PostGIS, and Redis. Now that setup had to keep running outside my laptop.
From that point, the standard changed. “The server starts locally” was not enough. Data collection had to run while I slept. Deployments had to follow the same order every time. When something broke, I needed to know where to look first.
Personal projects often stop here. It is easy to think, “It is my app and my server, so I can check it when something goes wrong.” But an API called by an App Store app has a different standard. Users do not need to know whether the server is at home or in the cloud, and stale values or empty screens make the app hard to trust.
A server at home was still a production environment
I decided to run the Hangangjari backend on a mini PC at home.
Moving to the cloud would have been more familiar and convenient. Still, I did not want this project to end with only the app. I wanted to run a small product end to end: server startup, deployment, monitoring, incident checks, backup, and recovery.
At first, the setup was close to Docker Compose. I ran Postgres, Redis, API, and workers in the local development environment and deployed something similar to the mini PC.
But once I treated it as a server people would use from outside, the questions multiplied.
- When should migrations run?
- How should API and workers be deployed separately?
- How should Postgres and Redis be managed?
- What should be checked after deployment?
- If the API dies from outside, how do I distinguish a Cloudflare Tunnel issue, a K3s issue, and an app issue?
- Where do logs and metrics live?
- How do I roll back a bad deployment?
As these questions accumulated, Cloudflare Tunnel, K3s, ArgoCD, local CI, and a deployment-state repository entered the system.
External requests pass through Cloudflare edge and Tunnel into the K3s ingress on the mini PC. I did not expose the origin server directly; the tunnel maintains the connection. I also kept the user request path separate from the operator maintenance path.
CI writes an image tag that passed lint, test, and build into the deployment-state repository. ArgoCD then reconciles the K3s cluster to that tag. I added Prometheus and Grafana for metrics, and organized log pipelines plus backup and recovery routines.
For a small app, this can look excessive. But one goal of this project was to take a small service all the way to something operable, so the process itself mattered. Using a mini PC did not reduce operational responsibility. If anything, it made the parts I had to own more visible.
The app did not end with one binary uploaded to the App Store. The API, data collection, cache, notifications, deployment path, operational configuration, health checks, logs, metrics, and backups were all part of the product.
A running process was not enough
A mini PC lowers cost, but it makes responsibility clearer. Things that a cloud console can hide behind buttons have to be decided directly: how to detect a full disk, whether services start after reboot, where DB backups are stored, and whether a bad deployment can be rolled back.
So I did not use “the process is running” as the operational standard. Even when I was away, I needed to be able to check:
- Is the API alive?
- Are workers running at the scheduled times?
- Is the last successful collection too old?
- Are DB and Redis healthy?
- Is the deployed image actually reflected?
- Is there a defined order for checking layers when something goes wrong?
After that, logs and metrics were no longer decorations. Without them, an incident does not start with fixing the problem; it starts with guessing where the problem is. Once users begin using even a personal project, “it works on my machine” is no longer enough.
Automation reduced mistakes more than it increased speed
I did not add CI/CD because it looked impressive. If I manually built images, SSHed into the server, and restarted things every time, I would eventually skip a step. Before launch especially, small fixes happen often. Copy changes, API response adjustments, worker interval changes, and redeployments repeat.
If the deployment procedure depends on memory, each small change becomes more anxious. When lint, test, build, image build, deployment-state update, and ArgoCD reconciliation have a defined order, even small fixes go out through the same path. Automation improved speed, but more importantly it reduced my own mistakes.
The most frequent work in building the operating environment was not adding new technology. It was reducing repeated mistakes. Make a deployment that succeeded once succeed almost the same way next time, and make problems checkable in the same order. Even for a small service, having that much structure made launch preparation much calmer.
Only after that could I move toward release. The server could not merely be lucky enough to be running. I needed to be able to deploy it again and verify it before putting the app outside.
Publishing to the App Store reduced the promise again
Looking back, the launch was not a process of adding more features. It was a process of widening the initial “Yeouido parking” problem into the whole Hangang outing context, then narrowing it again into words I could actually show and support in the App Store.
- 05.12 - PRD cleanup: The starting point was Yeouido parking. I first held onto the problem of quickly checking “can I go now?” through a widget.
- 05.17 - 0.1.0: The first app shape for checking parking status existed.
- 05.19 - General mode: Events, facilities, notices, and directions expanded the scope into “things to check before and after an outing.”
- 05.20-23 - Operations cleanup: API and workers were separated, and deployment plus observability became repeatable routines.
- 06.09-12 - Launch preparation: Translations, screenshots, brand site, and App Store metadata were aligned with real features.
Even after the app features were mostly complete, it was not immediately ready to launch.
App Store Connect asks for more than expected: app name, subtitle, description, keywords, privacy policy, support page, age rating, App Privacy, and review notes.
Screenshots, TestFlight builds, real-device validation, and localized metadata were also required.
During this process, Hangangjari’s wording changed a lot.
Early on, parking was much further forward. In public metadata, I summarized it as a way to see Hangang Park outing information at a glance. The app description no longer led with only parking; it included eleven Hangang parks, parking availability, congestion flow, public events, facilities, notices, widgets, and notifications.
I also made a brand site. At first, I thought a support page and privacy policy would be enough. But when someone who does not know the app arrives, the page needs to explain quickly what the app does.
So I built a multilingual brand site at hangangjari.app and made it show app screens, widgets, forecasts, notifications, directions, and official data sources.
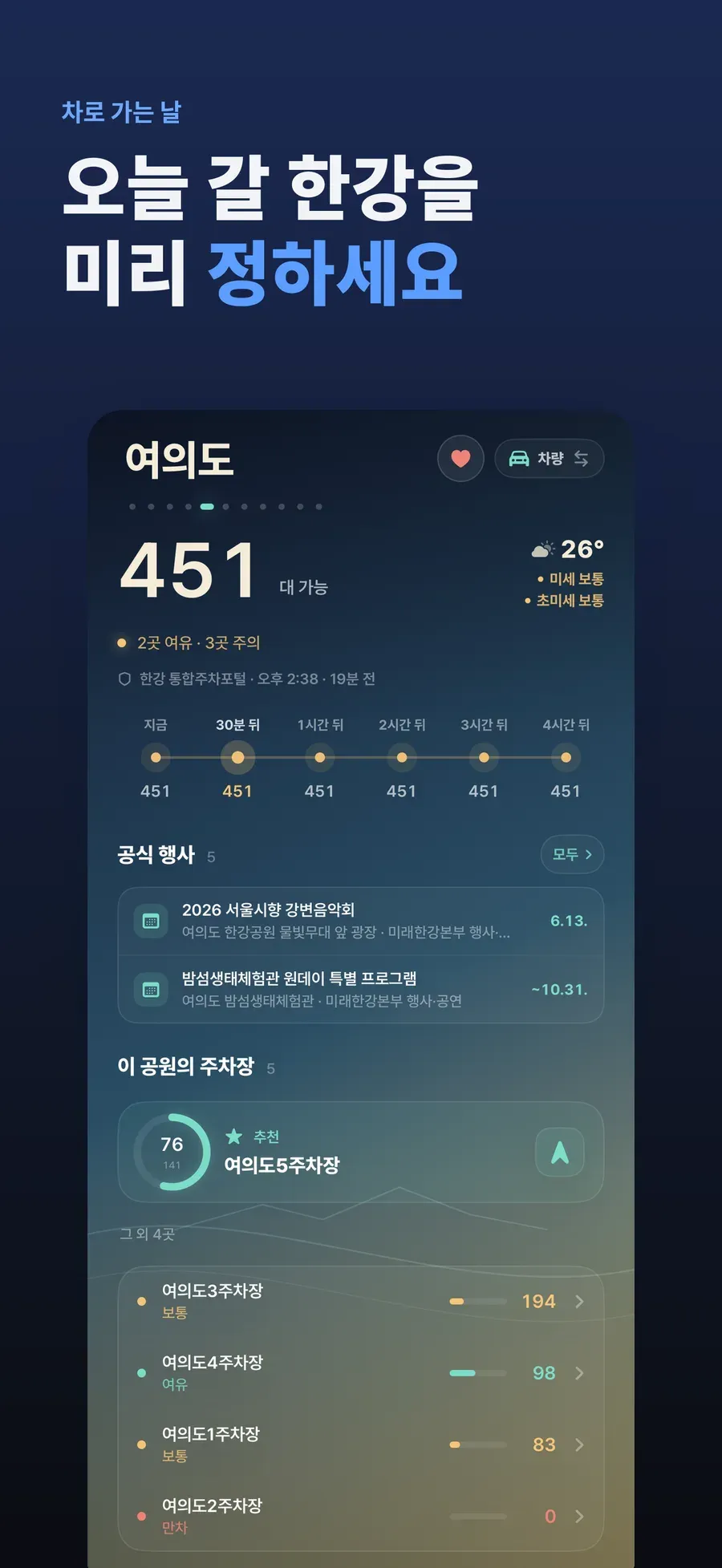
The last few days before release were more about verification and cleanup than code. I made localized screenshots, uploaded them to App Store Connect, and created TestFlight candidates while incrementing build numbers.
After choosing the final candidate, I aligned the release tag and public metadata. I also checked again that the App Store name, description, and privacy disclosures did not drift from the real functionality.
At that point, one thing became clear. Launch preparation was not an appendix to development. The name, description, legal notices, privacy explanation, screenshots, support page, and brand site are the first parts of the product a user meets before opening the app.
At the end, I reduced explanation more than features
Near the end, I spent more time reducing and aligning explanations than adding features. A long App Store description became less clear. Screenshot copy had to be short. The privacy policy and support page had to be accurate without exaggeration. I also could not hide that the app was not official.
As a developer, it is easy to gloss over these things because I already know the app. But before installing, users first see the name, icon, screenshots, description, and privacy disclosure. If that first impression does not build trust, good features have a hard start.
So launch preparation felt like separate product development. Checking whether the code runs and explaining the app so a stranger can trust and install it are different kinds of work. Hangangjari was also practice in finishing that second kind of work.
Operations and launch were not separate stages. The server had to run reliably before the App Store description could match real behavior, and the privacy and support pages had to be accurate without overpromising.
The app I wanted to publish all the way
Hangangjari is a free app. It can be used without login, and favorites are stored on the device. Location is used on-device only when sorting nearby parks and parking lots. There are anonymous usage events for product quality checks, but the app was built from the beginning to avoid unnecessary accounts and personal data.
It is not an app meant to make money. Still, I had a clear reason to finish it.
I wanted to fix something that bothered me. And if it was useful not only to me, I wanted to share it.
For people in Seoul, the Han River is extremely familiar. That familiarity means people somehow get there even when information is scattered. But if you bring a car, choose a park for the first time, visit as a foreign tourist, or go out with children on a weekend, one small piece of information can change whether you leave.
- Which park should I go to?
- Can I take the car?
- Is it crowded right now?
- Are there events today?
- Where are the restrooms and convenience facilities?
- Which map app should directions open in?
Hangangjari does not want to make definitive decisions for people. It wants to gather the reasons that reduce hesitation before leaving and wandering after arrival.
What I learned from this project is close to that.
- Following a small inconvenience to the end can become a wider product than expected.
- A public-data app does not stop at showing data; it has to explain the limits of that data.
- Client architecture was less about screen layout and more about letting app, widgets, and notifications inherit the same information.
- The backend did not stop at building APIs; it included data trust and collection failure handling.
- The smaller the surface, such as widgets and notifications, the more important it is to decide what to remove.
- Deployment, observability, backups, and release notes are part of the product even in a personal project.
There is a phrase I often repeat to myself.
If something is inconvenient, fix it. If it is useful, share it.
Hangangjari was built with that thought.
It still has many gaps. The data should be more accurate, the wording should become easier, and Android is needed too. But at least one habit of mine changed: when going to the Han River, I stopped opening the web page every time and started checking the app and widget.
If other people can use it comfortably too, this project is meaningful enough.
The conclusion is modest, but that fits Hangangjari. This is not a story about building a large platform. It is a story about pushing a frequent inconvenience all the way to an app launch.
Running a small server, submitting to the App Store, organizing explanations, and checking everything again were all part of one launch. Launch day was not the end; it was the day this small tool began needing to keep running reliably on other people’s phones.
This is not a story about building a large server. Even a small server becomes part of the product once users arrive, including deployment, observability, recovery, and explanation. Publishing means showing the feature and also checking whether I can keep taking responsibility for it.
Links
Share
No comments yet. You can leave the first one.
Pending review